基本概念
先普及几个词汇
Lexer: 词法分析器。Lexical analyzer,简称Lexer
Literals :字面量
Symbol: 词法符号
Dictionary: 字典
tokenize: 标记化
lexeme: 词素。词素是组成编程语言的最小的有意义的单元实体。生成的词素最后会组成一个token列表,每一个token都包含一个lexeme
Token: 标记。一个字符串,是构成源代码的最小单位。从输入字符流中生成标记的过程叫作标记化(tokenization),在这个过程中,词法分析器还会对标记进行分类。
LexerEngine
词法分析引擎
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
| @RequiredArgsConstructor
public final class LexerEngine {
private final Lexer lexer;
public String getInput() {
return lexer.getInput();
}
public void nextToken() {
lexer.nextToken();
}
public Token getCurrentToken() {
return lexer.getCurrentToken();
}
public String skipParentheses(final SQLStatement sqlStatement) {
StringBuilder result = new StringBuilder("");
int count = 0;
if (Symbol.LEFT_PAREN == lexer.getCurrentToken().getType()) {
final int beginPosition = lexer.getCurrentToken().getEndPosition();
result.append(Symbol.LEFT_PAREN.getLiterals());
lexer.nextToken();
while (true) {
if (equalAny(Symbol.QUESTION)) {
sqlStatement.increaseParametersIndex();
}
if (Assist.END == lexer.getCurrentToken().getType() || (Symbol.RIGHT_PAREN == lexer.getCurrentToken().getType() && 0 == count)) {
break;
}
if (Symbol.LEFT_PAREN == lexer.getCurrentToken().getType()) {
count++;
} else if (Symbol.RIGHT_PAREN == lexer.getCurrentToken().getType()) {
count--;
}
lexer.nextToken();
}
result.append(lexer.getInput().substring(beginPosition, lexer.getCurrentToken().getEndPosition()));
lexer.nextToken();
}
return result.toString();
}
public void accept(final TokenType tokenType) {
if (lexer.getCurrentToken().getType() != tokenType) {
throw new SQLParsingException(lexer, tokenType);
}
lexer.nextToken();
}
public boolean equalAny(final TokenType... tokenTypes) {
for (TokenType each : tokenTypes) {
if (each == lexer.getCurrentToken().getType()) {
return true;
}
}
return false;
}
public boolean skipIfEqual(final TokenType... tokenTypes) {
if (equalAny(tokenTypes)) {
lexer.nextToken();
return true;
}
return false;
}
public void skipAll(final TokenType... tokenTypes) {
Set<TokenType> tokenTypeSet = Sets.newHashSet(tokenTypes);
while (tokenTypeSet.contains(lexer.getCurrentToken().getType())) {
lexer.nextToken();
}
}
public void skipUntil(final TokenType... tokenTypes) {
Set<TokenType> tokenTypeSet = Sets.newHashSet(tokenTypes);
tokenTypeSet.add(Assist.END);
while (!tokenTypeSet.contains(lexer.getCurrentToken().getType())) {
lexer.nextToken();
}
}
public void unsupportedIfEqual(final TokenType... tokenTypes) {
if (equalAny(tokenTypes)) {
throw new SQLParsingUnsupportedException(lexer.getCurrentToken().getType());
}
}
public void unsupportedIfNotSkip(final TokenType... tokenTypes) {
if (!skipIfEqual(tokenTypes)) {
throw new SQLParsingUnsupportedException(lexer.getCurrentToken().getType());
}
}
public DatabaseType getDatabaseType() {
if (lexer instanceof MySQLLexer) {
return DatabaseType.MySQL;
}
if (lexer instanceof OracleLexer) {
return DatabaseType.Oracle;
}
if (lexer instanceof SQLServerLexer) {
return DatabaseType.SQLServer;
}
if (lexer instanceof PostgreSQLLexer) {
return DatabaseType.PostgreSQL;
}
throw new UnsupportedOperationException(String.format("Cannot support lexer class: %s", lexer.getClass().getCanonicalName()));
}
}
|
Lexer
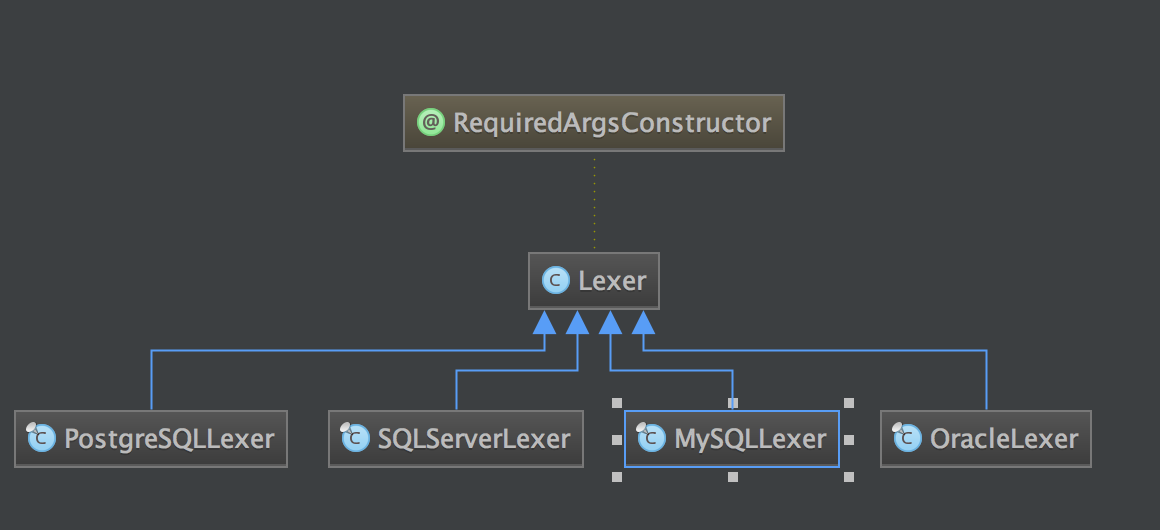
1
2
3
4
5
6
7
8
9
10
11
12
13
| @RequiredArgsConstructor
public class Lexer {
@Getter
private final String input;
private final Dictionary dictionary;
private int offset;
@Getter
private Token currentToken;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public final void nextToken() {
skipIgnoredToken();
if (isVariableBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanVariable();
} else if (isNCharBegin()) {
currentToken = new Tokenizer(input, dictionary, ++offset).scanChars();
} else if (isIdentifierBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanIdentifier();
} else if (isHexDecimalBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanHexDecimal();
} else if (isNumberBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanNumber();
} else if (isSymbolBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanSymbol();
} else if (isCharsBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanChars();
} else if (isEnd()) {
currentToken = new Token(Assist.END, "", offset);
} else {
throw new SQLParsingException(this, Assist.ERROR);
}
offset = currentToken.getEndPosition();
}
|
标识符开头:字母、’`’、’_’、’$’ 开头的
skipIgnoredToken
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| private void skipIgnoredToken() {
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
while (isHintBegin()) {
offset = new Tokenizer(input, dictionary, offset).skipHint();
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
}
while (isCommentBegin()) {
offset = new Tokenizer(input, dictionary, offset).skipComment();
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
}
}
|
skipHint
处理开头*/结束的东西
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public int skipHint() {
return untilCommentAndHintTerminateSign(HINT_BEGIN_SYMBOL_LENGTH);
}
private int untilCommentAndHintTerminateSign(final int beginSymbolLength) {
int length = beginSymbolLength;
while (!isMultipleLineCommentEnd(charAt(offset + length), charAt(offset + length + 1))) {
if (CharType.isEndOfInput(charAt(offset + length))) {
throw new UnterminatedCharException("*/");
}
length++;
}
return offset + length + COMMENT_AND_HINT_END_SYMBOL_LENGTH;
}
private boolean isMultipleLineCommentEnd(final char ch, final char next) {
return '*' == ch && '/' == next;
}
|
处理注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public int skipComment() {
char current = charAt(offset);
char next = charAt(offset + 1);
if (isSingleLineCommentBegin(current, next)) {
return skipSingleLineComment(COMMENT_BEGIN_SYMBOL_LENGTH);
} else if ('#' == current) {
return skipSingleLineComment(MYSQL_SPECIAL_COMMENT_BEGIN_SYMBOL_LENGTH);
} else if (isMultipleLineCommentBegin(current, next)) {
return skipMultiLineComment();
}
return offset;
}
private boolean isSingleLineCommentBegin(final char ch, final char next) {
return '/' == ch && '/' == next || '-' == ch && '-' == next;
}
private int skipSingleLineComment(final int commentSymbolLength) {
int length = commentSymbolLength;
while (!CharType.isEndOfInput(charAt(offset + length)) && '\n' != charAt(offset + length)) {
length++;
}
return offset + length + 1;
}
|
scanVariable
处理变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public Token scanVariable() {
int length = 1;
if ('@' == charAt(offset + 1)) {
length++;
}
while (isVariableChar(charAt(offset + length))) {
length++;
}
return new Token(Literals.VARIABLE, input.substring(offset, offset + length), offset + length);
}
private boolean isVariableChar(final char ch) {
return isIdentifierChar(ch) || '.' == ch;
}
private boolean isIdentifierChar(final char ch) {
return CharType.isAlphabet(ch) || CharType.isDigital(ch) || '_' == ch || '$' == ch || '#' == ch;
}
|
scanIdentifier
处理标识符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| public Token scanIdentifier() {
if ('`' == charAt(offset)) {
int length = getLengthUntilTerminatedChar('`');
return new Token(Literals.IDENTIFIER, input.substring(offset, offset + length), offset + length);
}
int length = 0;
while (isIdentifierChar(charAt(offset + length))) {
length++;
}
String literals = input.substring(offset, offset + length);
if (isAmbiguousIdentifier(literals)) {
return new Token(processAmbiguousIdentifier(offset + length, literals), literals, offset + length);
}
return new Token(dictionary.findTokenType(literals, Literals.IDENTIFIER), literals, offset + length);
}
private int getLengthUntilTerminatedChar(final char terminatedChar) {
int length = 1;
while (terminatedChar != charAt(offset + length) || hasEscapeChar(terminatedChar, offset + length)) {
if (offset + length >= input.length()) {
throw new UnterminatedCharException(terminatedChar);
}
if (hasEscapeChar(terminatedChar, offset + length)) {
length++;
}
length++;
}
return length + 1;
}
private boolean hasEscapeChar(final char charIdentifier, final int offset) {
return charIdentifier == charAt(offset) && charIdentifier == charAt(offset + 1);
}
private TokenType processAmbiguousIdentifier(final int offset, final String literals) {
int i = 0;
while (CharType.isWhitespace(charAt(offset + i))) {
i++;
}
if (DefaultKeyword.BY.name().equalsIgnoreCase(String.valueOf(new char[] {charAt(offset + i), charAt(offset + i + 1)}))) {
return dictionary.findTokenType(literals);
}
return Literals.IDENTIFIER;
}
|
scanHexDecimal
处理十六进制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public Token scanHexDecimal() {
int length = HEX_BEGIN_SYMBOL_LENGTH;
if ('-' == charAt(offset + length)) {
length++;
}
while (isHex(charAt(offset + length))) {
length++;
}
return new Token(Literals.HEX, input.substring(offset, offset + length), offset + length);
}
private boolean isHex(final char ch) {
return ch >= 'A' && ch <= 'F' || ch >= 'a' && ch <= 'f' || CharType.isDigital(ch);
}
|
scanNumber
处理数字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public Token scanNumber() {
int length = 0;
if ('-' == charAt(offset + length)) {
length++;
}
length += getDigitalLength(offset + length);
boolean isFloat = false;
if ('.' == charAt(offset + length)) {
isFloat = true;
length++;
length += getDigitalLength(offset + length);
}
if (isScientificNotation(offset + length)) {
isFloat = true;
length++;
if ('+' == charAt(offset + length) || '-' == charAt(offset + length)) {
length++;
}
length += getDigitalLength(offset + length);
}
if (isBinaryNumber(offset + length)) {
isFloat = true;
length++;
}
return new Token(isFloat ? Literals.FLOAT : Literals.INT, input.substring(offset, offset + length), offset + length);
}
|
scanSymbol
处理符号包起来的
其中Symbol后面讲述
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public Token scanSymbol() {
int length = 0;
while (CharType.isSymbol(charAt(offset + length))) {
length++;
}
String literals = input.substring(offset, offset + length);
Symbol symbol;
while (null == (symbol = Symbol.literalsOf(literals))) {
literals = input.substring(offset, offset + --length);
}
return new Token(symbol, literals, offset + length);
}
|
scanChars
处理单引号或双引号扩起来的
1
2
3
4
5
6
7
8
| public Token scanChars() {
return scanChars(charAt(offset));
}
private Token scanChars(final char terminatedChar) {
int length = getLengthUntilTerminatedChar(terminatedChar);
return new Token(Literals.CHARS, input.substring(offset + 1, offset + length - 1), offset + length);
}
|
Token
Token有三个参数:
- type(TokenType): INT, FLOAT, HEX, CHARS, IDENTIFIER, VARIABLE
- literals(String): 字面量
- endPosition(int): 字符结束的位置
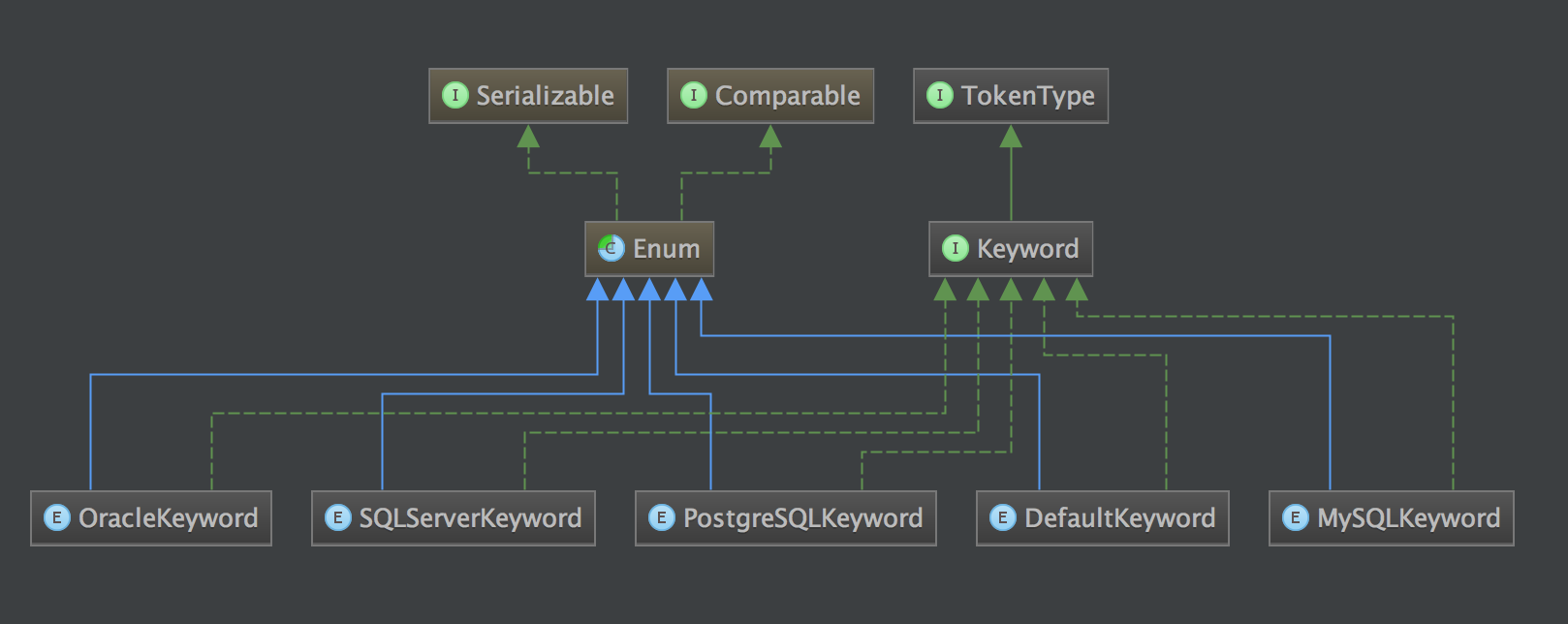
Dictionary
字典
包含一个map,包含每个关键字,Keyword的实现类都是一些枚举常量
1
2
|
private final Map<String, Keyword> tokens = new HashMap<>(1024);
|
比如MySQLLexer 实现的时候就是使用MySQLKeyword.values()作为构造参数,构造后填充tokens
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public Dictionary(final Keyword... dialectKeywords) {
fill(dialectKeywords);
}
private void fill(final Keyword... dialectKeywords) {
for (DefaultKeyword each : DefaultKeyword.values()) {
tokens.put(each.name(), each);
}
for (Keyword each : dialectKeywords) {
tokens.put(each.toString(), each);
}
}
}
|
下面这两个方法用来进行词法分析的时候根据字典识别出类型。
1
2
3
4
5
6
7
8
9
10
11
12
| TokenType findTokenType(final String literals, final TokenType defaultTokenType) {
String key = null == literals ? null : literals.toUpperCase();
return tokens.containsKey(key) ? tokens.get(key) : defaultTokenType;
}
TokenType findTokenType(final String literals) {
String key = null == literals ? null : literals.toUpperCase();
if (tokens.containsKey(key)) {
return tokens.get(key);
}
throw new IllegalArgumentException();
}
|
Symbol
词法符号
包含一个map,包含每个符号,Symbol的都是一些枚举常量
1
| private static Map<String, Symbol> symbols = new HashMap<>(128);
|
获取符号具体类型
1
2
3
| public static Symbol literalsOf(final String literals) {
return symbols.get(literals);
}
|